개요
프로그램이 여러 개의 CPU 코어에서 돌아갈 수 있게 소스 코드를 작성하면, 생산성을 높이는 데 도움이 됩니다. 필요한 연산을 여러 개의 코어들이 나누어서 수행하기 때문에, 프로그램 실행에 소요되는 시간이 줄어드는 효과가 있는 것이죠. CPU에서 구동되는 프로그램을 병렬화 하는데 있어서 MPI (Message Passing Interface)와 OpenMP가 많이 사용되는데요. 이번 포스팅에서는 MPI를 이용한 병렬 프로그래밍에 대해 다뤄볼까 합니다. MPI는 C언어, C++ 및 포트란 프로그램 내에서 프로세스 간의 데이터 전달을 정의함으로써, 병렬 프로그래밍을 가능하게 하는 인터페이스입니다.
MPI와 OpenMP의 가장 큰 차이점 중 하나는 메모리를 공유하는지의 여부가 될 것입니다. OpenMP의 경우 모든 프로세스 또는 스레드 (thread)에서 메모리에 할당된 변수들을 공유하며 접근이 가능합니다. 예를 들어서 정수형 (int) 변수 a를 선언하고 값을 10으로 정했다면, 모든 스레드는 해당 정수형 변수 a의 값을 10으로 인지하게 되죠. 프로그램 중간에 값을 바꾸는 경우에도, 모든 스레드에 똑같이 적용이 됩니다.
반면에 MPI를 이용한 병렬 프로그램에서는 소스코드에서 하나의 변수로 선언된 것일지라도, 각각의 프로세스가 이름만 같은 별도의 변수를 가지며 그 값도 서로 독립적입니다. 서로 다른 프로세스간에 데이터를 주고받기 위해서는 별도의 함수를 호출할 필요가 있죠. 여기에 대해서는 아래에서 더 자세하게 짚어보도록 하겠습니다. 데이터 송수신을 직접 지정해야 하는 번거로움이 있지만, 프로세스들이 동일한 물리적 메모리를 공유할 필요가 없다는 장점이 있습니다. 그래서 여러 개의 노드 (컴퓨터)가 연결된 슈퍼컴퓨터를 사용한다면 MPI가 특히 유용합니다.
MPI 라이브러리 설치
당연한 얘기지만, MPI를 사용하기 위해서는 라이브러리가 필요한데요. Open MPI와 MPICH가 많이 사용됩니다. 대부분의 슈퍼컴퓨터에서는 MPI 라이브러리들이 미리 설치되어 있어서, 홈 디렉토리에 있는 .bashrc 파일 등을 이용해 로드하기만 하면 됩니다. 설치 및 사용에 있어서 주의할 점이 있다면, Open MPI와 MPICH가 가진 기능들이 상당부분 겹치기 때문에 충돌이 일어날 수 있다는 것입니다. 헤더파일과 라이브러리를 자동으로 탐색하도록 미리 설정된 경로에 설치할 경우, 둘 중 하나만 설치하는 것을 개인적으로 권장합니다.
리눅스나 유닉스의 경우 웹사이트로부터 소스 파일을 받아서 라이브러리를 빌드할 수 있습니다.
Open MPI
Open MPI: Open Source High Performance Computing
www.open-mpi.org
MPICH
MPICH | High-Performance Portable MPI
MPICH is a high performance and widely portable implementation of the Message Passing Interface (MPI) standard. MPICH and its derivatives form the most widely used implementations of MPI in the world. They are used exclusively on nine of the top 10 superco
www.mpich.org
macOS에서는 Homebrew를 통해서도 설치할 수 있습니다. Open MPI와 MPICH의 Homebrew 패키지 이름은 각각 open-mpi 및 mpich 이므로, 다음과 같이 brew install 명령어를 통해서 설치가 가능합니다.
- Open MPI 설치
brew install open-mpi - MPICH 설치
brew install mpich
이렇게 Homebrew를 통해서 설치하는 경우, Open MPI와 MPICH 둘 다 설치해 버리면 충돌이 일어날 수 있습니다. 이는 brew info 명령어로 패키지 정보를 확인할 때도 언급되는 사항이죠. 설치가 완료되면 brew list를 이용해서 목록을 확인했을때, MPI 라이브러리가 있는 것을 볼 수 있습니다.
윈도우 사용자의 경우 vcpkg를 통해 라이브러리를 설치하면 비주얼 스튜디오에서 사용이 가능한데요. vcpkg를 사용해서 C언어 및 C++ 라이브러리들을 설치하고 관리하는 방법에 대해서는 다음 포스팅을 참고하면 좋습니다.
vcpkg로 비주얼 스튜디오 라이브러리 설치하기
여기서는 vcpkg를 사용해서 라이브러리를 설치하고 이를 MS 비주얼 스튜디오에서 사용하는 법에 대해 알아봅시다. vcpkg는 C언어 및 C++ 라이브러리를 편리하게 관리할 수 있도록 도와주는 프로그램
swstar.tistory.com
MPI를 이용해서 병렬 프로그램을 작성하기 위해서는, 다음과 같이 MPI 헤더 파일을 C언어 또는 C++ 소스 코드에 포함시켜야 합니다.
#include<mpi.h>
그리고 MPI 프로그램을 컴파일 및 링크할 때는 다음과 같은 별도의 컴파일러를 사용해야 합니다.
C언어 : mpicc
C++ : mpicxx
포트란 : mpifort
MPI 프로그램을 빌드하고 나면, mpiexec라는 별도의 프로그램을 통해서 실행을 해야 되는데요. 이 때 -n 옵션을 통해서 프로세스 갯수를 지정해 줄 필요가 있습니다. 예를 들어서 쿼드코어를 사용하는 개인용 컴퓨터에서 CPU를 풀가동하고 싶다면, 4개로 설정하면 되겠습니다.
mpiexec -n [프로세스 갯수] [실행파일 이름] [명령행 인자들]
초기화 및 프로세스 랭크
MPI 병렬 프로그램에서 가장 기본이 되는 함수들은 MPI의 초기화를 담당하는 MPI_Init 함수와 MPI를 종료시키기 위한 MPI_Finalize 함수가 될 것입니다.
간단한 예시로서 "Hello World!" C언어 프로그램을 MPI를 이용해서 만들어봅시다.
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
// MPI 헤더 파일
#include<mpi.h>
int n_size_; // 프로세스의 총 갯수
int n_rank_; // 각 프로세스에 부여된 랭크
int main(int argc, char *argv[]) {
// MPI 초기화
MPI_Init(&argc, &argv);
// 프로세스 총 갯수 및 각 프로세스의 랭크
MPI_Comm_size(MPI_COMM_WORLD, &n_size_);
MPI_Comm_rank(MPI_COMM_WORLD, &n_rank_);
if (n_rank_ == 0) {
// 랭크가 0 인 프로세스
fprintf(stdout,
"We have %d processess.\n", n_size_);
}
// 모든 프로세스가 여기에 도달할 때 까지 대기
MPI_Barrier(MPI_COMM_WORLD);
// Hello World!
fprintf(stdout,
" [PROCESSOR %d] : Hello World!\n", n_rank_);
// MPI 종료
MPI_Finalize();
return 0;
}
위에도 말했다시피 MPI 프로그램의 시작은 초기화를 위한 MPI_Init 함수이고, 명령행 인자들의 포인터를 인자로 넘겨주게 됩니다. 그 다음으로는 프로세스의 총 갯수와 각 프로세스의 랭크를 알 필요가 있는데요. 프로세스의 랭크는 간단히 말하자면 각 프로세스의 아이디 역할을 하는 정수형 변수로서, 0 에서 [프로세스 총 갯수]-1 사이의 값을 가집니다.
예를 들어서 프로세스의 총 갯수와 각 프로세스의 랭크를 저장하기 위한 변수인 n_size_ 와 n_rank_ 를 각각 선언했다면, 이들의 포인터를 다음과 같이 MPI 함수에 전달할 수 있습니다.
MPI_Comm_size(MPI_COMM_WORLD, &n_size_);
MPI_Comm_rank(MPI_COMM_WORLD, &n_rank_);
여기서 n_size_ 는 모든 프로세스가 당연히 동일한 값을 가지지만, n_rank_ 의 경우 프로세스마다 다른 값을 가지게 됩니다. 이 변수들을 적절히 활용해서 프로세스 간의 데이터 전달을 제어하는 거죠.
추가로 MPI_COMM_WORLD 라는 것이 등장하는데요. MPI에서는 서로 데이터를 주고받는 프로세스들의 집합체로서 커뮤니케이터 (communicator)라는 개념을 도입하고 있습니다. MPI_COMM_WORLD는 이 커뮤니케이터 중 하나로서, 프로그램의 구동에 사용되는 모든 프로세스의 집합입니다. 다시 말해서 모든 프로세스는 MPI_COMM_WORLD에 소속되어 있으므로, MPI_COMM_WORLD 커뮤니케이터를 인자로 MPI 함수들을 호출하면 모든 프로세스가 상호간에 데이터를 주고받을 수 있게 되죠.
맨 먼저 프로세스가 모두 몇 개 있는지를 출력하고 싶은데, 출력하는 구문만 넣게 되면 모든 프로세스가 그걸 실행하게 됩니다. 그래서 랭크의 값이 0인 프로세스에서만 출력할 수 있도록 n_rank_ 를 이용한 조건문을 추가했습니다. 그래서 프로세스의 총 갯수가 몇개인지에 대한 메시지는 한 번만 보면 되는거죠.
이제 "Hello World!"를 출력할 차례인데요. 소스코드 상에서는 프로세스의 총 갯수가 출력된 이후에 등장합니다만, 랭크가 0이 아닌 프로세스가 "Hello World!" 메시지를 먼저 출력해버릴 가능성이 있습니다. 이 때 서로 다른 프로세스 간의 페이스를 조절하는 한 가지 방법으로는 MPI_Barrier라는 함수를 호출하는 것입니다.
MPI_Barrier(MPI_COMM_WORLD);
인자로 들어가는 커뮤니케이터에 소속된 모든 프로세스들이 MPI_Barrier가 호출된 구문에 도달할 때 까지 대기하게 됩니다. 여기에 MPI_COMM_WORLD를 인자로 넣게 되면, 모든 프로세스들이 동기화 되겠죠.
프로그램 main 함수의 끝에는 MPI_Finalize 함수를 호출하여 MPI를 종료하도록 합시다.
위의 "Hello World!" 코드를 컴파일하고 실행해 보면, 다음과 같은 결과를 얻을 수 있습니다.

소스 코드에는 "Hello World!"를 출력하는 구문이 하나밖에 없지만, 모든 프로세스가 이를 한 번씩 실행하므로 프로세스의 갯수만큼 출력되는 것을 볼 수 있습니다.
프로세스 간의 데이터 통신
서로 다른 랭크 값을 가진 프로세스들 사이에서 변수의 값들을 전달하는게 가능하고, 이를 위해서 MPI_Send 및 MPI_Recv 함수들을 사용할 수 있습니다. MPI_Send는 다른 프로세스에 데이터를 보내는 역할을 하는 반면에, MPI_Recv는 다른 프로세스로부터 데이터를 받아오는 데 사용됩니다. 이들은 다음과 같은 프로토타입과 매개변수들을 가지고 있습니다.
/* ptr_buf : 보내고자 하는 데이터들이
* 저장된 변수나 배열의 주소 (포인터)
* count : 데이터의 갯수
* 혹은 배열의 크기
* datatype : MPI 자료형
* target : 수신자 프로세스의 랭크 값
* tag : 태그
* comm : 커뮤니케이터 */
MPI_Send(void *ptr_buf,
int count,
MPI_Datatype datatype,
int target,
int tag,
MPI_Comm comm);
/* ptr_buf : 받고자 하는 데이터들이
* 저장된 변수나 배열의 주소 (포인터)
* count : 데이터의 갯수
* 혹은 배열의 크기
* datatype : MPI 자료형
* source : 발신자 프로세스의 랭크 값
* tag : 태그
* comm : 커뮤니케이터
* ptr_status : 수신 상태가 저장되는
* 구조체의 주소 (포인터) */
MPI_Recv(void *ptr_buf,
int count,
MPI_Datatype datatype,
int source,
int tag,
MPI_Comm comm,
MPI_Status *ptr_status);
송수신 함수에서 MPI 자료형을 나타내는 MPI_Datatype이 등장하는데요. C언어 자료형과 MPI 자료형들은 다음과 같이 대응됩니다.
- int 정수형
MPI_INT - short int 정수형
MPI_SHORT - long int 정수형
MPI_LONG - long long int 정수형
MPI_LONG_LONG_INT - unsigned int 정수형
MPI_UNSIGNED - unsigned long int 정수형
MPI_UNSIGNED_LONG - unsigned short int 정수형
MPI_UNSIGNED_SHORT - float 실수형
MPI_FLOAT - double 실수형
MPI_DOUBLE - long double 실수형
MPI_LONG_DOUBLE - char 문자형
MPI_CHAR - unsigned char 문자형
MPI_UNSIGNED_CHAR
송수신 함수에 공통으로 들어가는 또다른 인자로는 정수형 변수인 tag가 있습니다. 이 태그는 두 프로세스가 주고받는 많은 데이터들을 구분할 수 있게 하는 역할을 하기에, 서로 대응이 되는 MPI_Send와 MPI_Recv 함수에 들어가는 태그 값을 서로 일치시켜줄 필요가 있겠습니다.
데이터를 수신하는 MPI_Recv 함수에 맨 마지막으로 들어가는 인자는 MPI_Status라는 구조체의 포인터입니다. 이 구조체는 수신 상태에 대한 정보를 저장하기 위한 것으로서, 제대로 수신된 데이터의 갯수나 함수의 호출이 (모종의 이유로) 취소되었는지 등에 대한 정보를 담고 있죠.
MPI를 이용한 데이터 송수신에 있어서 가장 주의할 점 중의 하나는 MPI_Send와 MPI_Recv 함수 간의 대응이 잘 이루어져야 한다는 것입니다. 만약 MPI_Recv 함수를 통해 데이터를 수신하고자 하는데, 발신지가 되는 프로세스에서 MPI_Send함수를 통해 데이터를 보내지 않는다면, 프로그램은 멍때린 상태로 정지하게 됩니다.
이제 원주율을 계산하는 예제 프로그램을 소개해 볼까 합니다. 원주율의 값은 표준 수학 함수 라이브러리 내에서도 정의되어 있지만, 정적분을 통해서도 구할 수 있는데요.
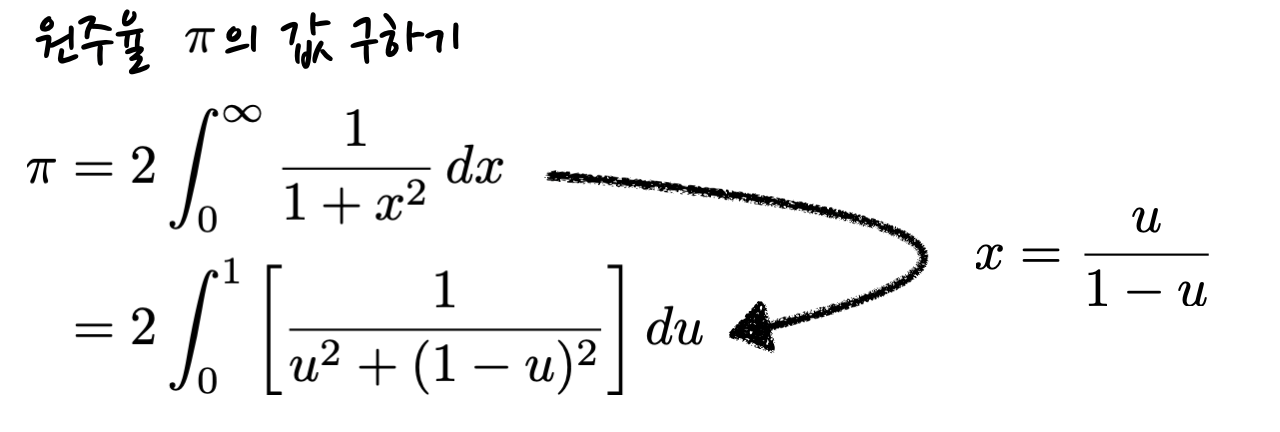
이는 역삼각함수인 아크탄젠트 함수의 도함수를 적분해서 원주율을 구하는 방법입니다. 자세한 사항이 궁금하시다면 다음 포스팅을 참고해 주세요.
수학 상식 : 원주율과 삼각함수
여기서는 기하학에 관련된 중요한 상수인 원주율과, 과학 및 공학 분야에서 가장 흔하게 접할 수 있는 주기함수인 삼각함수에 대해 얘기해볼까 합니다. 원주율과 호도법 먼저 유클리드 공간에
swstar.tistory.com
여기서는 적분 구간을 여러개로 나눈 다음, 프로세스들에게 할당하는 방식의 병렬 프로그램을 만들어 봅시다.
test1_pi_mpi.c [다운로드]
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<math.h>
// MPI 헤더 파일
#include<mpi.h>
int n_size_; // 프로세스의 총 갯수
int n_rank_; // 각 프로세스에 부여된 랭크
// 정밀도
double eps_precision = 1e-12;
// 적분 대상이 되는 함수
double func_integrand(double u);
int main(int argc, char *argv[]) {
// MPI 초기화
MPI_Init(&argc, &argv);
// 프로세스 총 갯수 및 각 프로세스의 랭크
MPI_Comm_size(MPI_COMM_WORLD, &n_size_);
MPI_Comm_rank(MPI_COMM_WORLD, &n_rank_);
if (n_rank_ == 0) {
// 랭크가 0 인 프로세스
fprintf(stdout,
"We have %d processes.\n", n_size_);
fprintf(stdout, "\n");
}
// 모든 프로세스가 여기에 도달할 때 까지 대기
MPI_Barrier(MPI_COMM_WORLD);
// MPI 통신을 위한 변수들
int tag;
MPI_Status status;
// 현재 단계의 원주율 값
double pi_now = 0.;
// 이전 단계의 원주율 값
double pi_prev;
// 현재 단계의 각 프로세스의 기여분
double pi_rank = 0.;
// 이전 단계의 각 프로세스의 기여분
double pi_rank_prev;
// 수렴 여부를 체크하기 위한 제어 변수
int converging = 0;
/* 각 프로세스에서 수치적분을 위한 구간 및
* 격자 간격 */
unsigned long int nbin_u = 1;
double u_min = (double)n_rank_ / (double)n_size_;
double u_max = u_min + 1. / (double)n_size_;
double delta_u = fabs(u_max - u_min);
int istep = 1;
/* 지정한 정밀도 이내에서 수렴할 때 까지
* 반복문 실행 */
while (converging == 0) {
pi_prev = pi_now;
pi_rank_prev = pi_rank;
pi_rank = 0.;
unsigned int iu;
// 수치적분 계산
if (istep == 1) {
for (iu = 0; iu < nbin_u; iu++) {
double u0 = u_min + delta_u * (double)iu;
double u1 = u0 + delta_u;
pi_rank +=
0.5 * delta_u * (func_integrand(u0) +
func_integrand(u1));
}
} else {
pi_rank = 0.5 * pi_rank_prev;
for (iu = 0; iu <= nbin_u; iu++) {
if (iu % 2 == 0) {
continue;
}
double u_now = u_min + delta_u * (double)iu;
pi_rank +=
delta_u * func_integrand(u_now);
}
}
pi_now = 0.;
if (n_rank_ == 0) {
// 랭크가 0 인 프로세스
/* 모든 프로세스의 기여분들을 취합하여
* 원주율의 값 계산 */
pi_now = pi_rank;
for (int irank = 1; irank < n_size_; irank++) {
tag = 1000 + irank;
double pi_add;
MPI_Recv(&pi_add, 1, MPI_DOUBLE, irank,
tag, MPI_COMM_WORLD, &status);
pi_now += pi_add;
}
fprintf(stdout,
" step %d : pi = %.12f\n", istep, pi_now);
} else {
// 랭크가 0 이 아닌 프로세스
tag = 1000 + n_rank_;
MPI_Send(&pi_rank, 1, MPI_DOUBLE, 0,
tag, MPI_COMM_WORLD);
}
if (n_rank_ == 0) {
// 랭크가 0 인 프로세스
// 수렴 체크
if (fabs(pi_now - pi_prev) <
0.5 * eps_precision *
fabs(pi_now + pi_prev)) {
converging = 1;
}
for (int irank = 1; irank < n_size_; irank++) {
tag = 2000 + irank;
MPI_Send(&converging, 1, MPI_INT, irank,
tag, MPI_COMM_WORLD);
}
} else {
// 랭크가 0 이 아닌 프로세스
tag = 2000 + n_rank_;
MPI_Recv(&converging, 1, MPI_INT, 0,
tag, MPI_COMM_WORLD, &status);
}
istep += 1;
// 적분 구간의 격자 갯수를 2배로 증가
nbin_u = 2 * nbin_u;
delta_u = 0.5 * delta_u;
}
// 모든 프로세스가 여기에 도달할 때 까지 대기
MPI_Barrier(MPI_COMM_WORLD);
if (n_rank_ == 0) {
// 랭크가 0 인 프로세스
fprintf(stdout, "\n");
fprintf(stdout, "pi from numerical integration\n");
fprintf(stdout, " > pi = %.12f\n", pi_now);
fprintf(stdout, "pi from C math library\n");
fprintf(stdout, " > pi = %.12f\n", M_PI);
}
// MPI 종료
MPI_Finalize();
return 0;
}
double func_integrand(double u) {
return 2. / (fabs(u * u) + fabs((1. - u) * (1. - u)));
}
프로그램을 컴파일하고 실행하면, 원주율의 값이 출력됩니다. 또한 여러 단계를 거치면서, 그 값이 더 정밀해지는 것도 확인이 가능하죠.

결과적으로 표준 수학 함수 라이브러리에 정의된 것과 상당히 근접한 값을 얻었습니다.
이상으로 간단한 예제 프로그램들을 통해서 MPI 병렬 프로그램의 뼈대를 이루는 요소들을 짚어보았습니다. 이번 포스팅에서는 C언어를 기준으로 이야기했습니다만, 앞서 언급한대로 C++ 및 포트란에서도 사용이 가능합니다. 뿐만 아니라 다양한 기능을 가진 함수들이 많이 있는데요. 이들은 다음 웹사이트에 PDF 문서로 잘 요약되어 있습니다.
people.cs.vt.edu/npolys/IT/FDI/bootcamp_2008/uva_mats
Index of /npolys/IT/FDI/bootcamp_2008/uva_mats
people.cs.vt.edu
병렬 프로그램을 작성하기 위한 또 다른 방법으로서 OpenMP에 대해 서론에서 언급했었는데요. OpenMP를 이용해 병렬 프로그램을 만드는 방법에 대해서는 다음 포스팅을 참고하면 좋습니다.
OpenMP C/C++ 를 이용한 병렬 프로그래밍
개요 여기서는 여러개의 CPU 코어를 동시에 사용하는 병렬 프로그램을 만들기 위한 방법 중 하나인 OpenMP에 대해 알아봅시다. OpenMP는 여러 개의 명령문들이 동시에 실행되는 프로그램을 작성하기
swstar.tistory.com
본문에서 명령행 인자가 몇 번 등장한 바 있습니다. 이는 프로그램을 실행할 때 실행파일의 이름과 함께 커맨드 라인에 입력하는 인자들이죠. 자세한 사항은 다음 포스팅에 소개되어 있습니다.
Command-line arguments (C/C++ 명령행 인자)
C++를 배우기 위해 책을 보는데, command-line arguments 즉 명령행 인자에 대한 내용이 있었습니다. 메인함수를 특별한 방법으로 정의해서, 프로그램을 실행시킬때 커맨드 라인에서 옵션을 지정해줄
swstar.tistory.com


